


By Koen Van Impe August 8, 2022
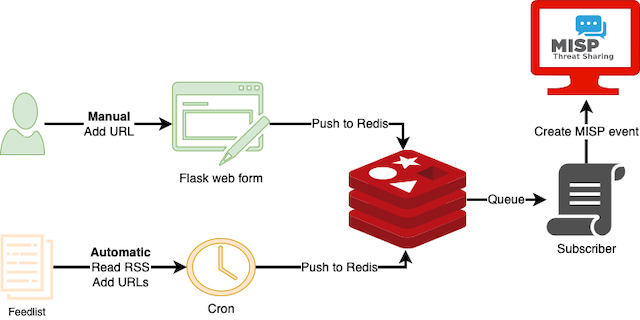
MISP web scraper
There are a lot of websites that regularly publish reports on new threats, campaigns or actors with useful indicators, references and context information. Unfortunately only a few publish information in an easily accessible and structured format, such as a MISP-feed. As a result, we often find ourself manually scraping these sites, and then copy-pasting this information in new MISP events. These tedious tasks are time-consuming and certainly not the most interesting aspect of CTI-work.
There is a tool that can support you: MISP-scraper. MISP-scraper is a Python script that
- Parses RSS feeds;
- Extracts the URLs from these feeds;
- Creates a MISP event for each URL. If the combination “event-URL” already exists then the event creation is skipped;
- Adds a MISP report (with the content of the URL) to the MISP event;
- And then uses the report feature to extract indicators and context from the web page;
- It is also possible to manually add URLs and outdated events are automatically deleted.

Components
MISP scraper implements
- The RSS reader (class MispScraperFeedparser) to read RSS feeds and extract URLs;
- A cron class to check for updates in the RSS feeds, as well as removing old events (MispScraperCron)
- A Flask web server that allows you to manually add a URL to scrape;
- Publishes URLs to Redis and subscribes to the queue (MispScraperRedis);
- And a class for MISP event creation (MispScraperEvent).
Workflow
The most common workflow is using the scraper as a cron job to read the list of RSS links of websites to monitor, push new URLs to Redis and then create MISP events and reports from these URLs.
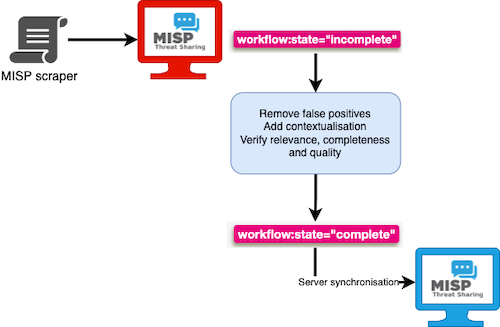
The MISP events are first in the workflow state ‘incomplete’. In general it is not such a good idea to create these events in your ‘main’ MISP. Ideally you create them in a ‘dirty’ MISP, do the curation of the events and then synchronise these events with your production MISP. If you want to know more about curation, then have a look at the FIRSTCON22 talk from NVISO In Curation We Trust. Once you have curated the events you can put them in the complete workflow state and then synchronise them with your production MISP.
Feedlist format
The feedlist is a JSON file with feeds consisting of a title and a URL.
{
"feeds": [
{
"title": "Proofpoint",
"url": "https://www.proofpoint.com/us/threat-insight-blog.xml"
},
{
"title": "Threatpost",
"url": "http://threatpost.com/feed"
}
]
}
If you need inspiration to complete your RSS feedlist then have a look at my OPML Security Feeds GitHub repository.
Prerequisites
MISP modules installed and enabled.
Installation
To install the scraper, clone the repository from GitHub, setup and activate a Python virtual environment, install the requirements and create an empty config file.
git clone https://github.com/cudeso/misp-scraper
cd misp-scraper
virtualenv scraper
source scraper/bin/activate
pip install -r requirements.txt
cp scraper.py.default scraper.py
Edit the scraper.py configuration file. Most settings are self-explanatory but you will need to change
- flask_secret_key: change with a random ‘strong’ key
- feedlist: the JSON file with the RSS feeds
- misp_key and misp_url: the API and URL of your MISP server
Then change the script location path in misp-scraper-flask.service and misp-scraper-subscribe.service to the path where you installed misp-scraper and the virtual environment. By default they use /home/ubuntu/misp-scraper/ (installation path) and /home/ubuntu/misp-scraper/scraper/ (virtual environment).
WorkingDirectory=/home/ubuntu/misp-scraper/
Environment=PATH=/home/ubuntu/misp-scraper/scraper/bin
ExecStart=/home/ubuntu/misp-scraper/scraper/bin/python /home/ubuntu/misp-scraper/misp-scraper.py flask (or subscribe)
Afterwards copy these two service scripts to the systemd/system directory.
sudo cp misp-scraper-flask.service /etc/systemd/system/
sudo cp misp-scraper-subscribe.service /etc/systemd/system/
Before you start the scripts it’s a good idea to verify that your configuration is correct. To do this you can start the subscriber component manually.
/home/ubuntu/misp-scraper/scraper/bin/python /home/ubuntu/misp-scraper/misp-scraper.py subscribe
If all goes well, you should get a message indicating the scraper started with the subscribe component. In the below sample the logging_level was set to “debug”. For production use you can switch to “error”.
2022-08-03 18:15:02,858 - MISP-Scraper - root - Starting with DEBUG
2022-08-03 18:15:03,108 - MISP-Scraper - root - Starting subscribe
Then enable and start the services.
sudo systemctl start misp-scraper-flask.service
sudo systemctl start misp-scraper-subscribe.service
sudo systemctl enable misp-scraper-flask.service
sudo systemctl enable misp-scraper-subscribe.service
The last thing left to do is to add the cron job to crontab. Except for rare cases, querying the RSS feeds every 4 or 8 hours should be sufficient.
* */4 * * * root /home/ubuntu/misp-scraper/scraper/bin/python /home/ubuntu/misp-scraper/misp-scraper.py cron
You can wait until the cron job executes (note that you can obviously also run the job manually) or use the Flask server to manually submit a URL to scrape. Point your browser to the IP and port defined in scraper.py with flask_address and flask_port. This should give you access to a form as below (feed title and URL are intentionally set to read-only).
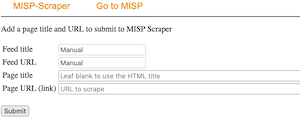
Enter a URL and click submit. Don’t worry about a title. If you leave the title field empty the script will use the HTML title instead.
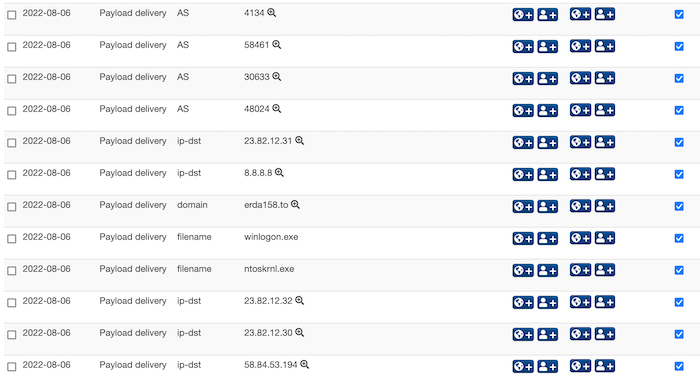
Sample event and report



Retention
There might be times when you don’t have sufficient time to go through the events. Instead of filling your MISP environment with events that are multiple days old you can have MISP scraper remove these old events automatically.
The setting misp_retentiontime dictates how long events (that are still in the workflow state ‘incomplete’) remain in the system. The ‘outdated’ events are removed from MISP every time you run the cron action.
Crawler user agent
The requests to the RSS feeds (via MISP scraper) and the websites (via the MISP report feature) use the HTTP user agent ‘python-requests’. Be aware that some websites block access via these user agents. This will prevent you from using MISP scraper on these sites. Where possible, it will report the error via a tag.

Other configuration options
MISP scraper uses a set of default tags on new events. You can define these in the configuration file via misp_scraper_tags.
misp_scraper_tags = ["misp:tool=\"misp-scraper\"", "osint:source-type=\"blog-post\"", "misp:event-type=\"collection\""]
Each new MISP event is prepended with a specific text. This is defined in misp_scraper_event.
misp_scraper_event = "Scraper"
The Flask server uses SSL and relies on the MISP (default) SSL key. You can always create your own certificates and configure them in
flask_certificate_file = "/etc/ssl/private/misp.local.crt"
flask_certificate_keyfile = "/etc/ssl/private/misp.local.key"
Extending the parser
Crawler
There are many extension option possible. One very useful extension lies in how the MISP reports are generated. Instead of using the Python user agent, you could transform this to a specific crawler, similar to the crawlers used by the AIL project (i.e., using the Splash -a scriptable browser- crawler).
“to_ids” flag
The to_ids flag is set according to the MISP defaults. The risk of false positives is however much higher with data coming from the web pages. After all, for a regular expression it’s not always possible to identify the extact context of an attribute.